KI hat die Art und Weise, wie wir arbeiten, revolutioniert und hilft bei allem, von Programmierung bis hin zu kreativem Schreiben. Viele dieser Tools sind jedoch auf Internetzugang und Drittanbieterdienste angewiesen, was Bedenken hinsichtlich der Privatsphäre und Zuverlässigkeit im Offline-Modus aufwirft.
An dieser Stelle kommt ein lokal-first Ansatz ins Spiel, wie zum Beispiel Ollama. Es ermöglicht Ihnen, KI unter Verwendung verschiedener LLMs direkt auf Ihrem Computer auszuführen, ohne eine Internetverbindung zu benötigen.
Egal, ob Sie ein Entwickler sind, der Unterstützung bei der Programmierung sucht, oder jemand, der erforschen möchte, was KI leisten kann, Ollama ist ein großartiges Werkzeug für Ihre Sammlung. Es unterstützt eine Vielzahl von Modellen und bietet eine API, mit der Sie programmgesteuert mit den Modellen interagieren können.
Installation
Um mit Ollama zu starten, müssen Sie es auf Ihrem Computer installieren.
Gehen Sie zur Download-Seite und wählen Sie den passenden Installer für Ihr Gerät. Es unterstützt macOS, Windows und Linux und bietet auch ein offizielles Docker-Image.
Wenn Sie macOS verwenden, können Sie es auch mit Homebrew installieren, indem Sie den folgenden Befehl ausführen:
brew install ollama
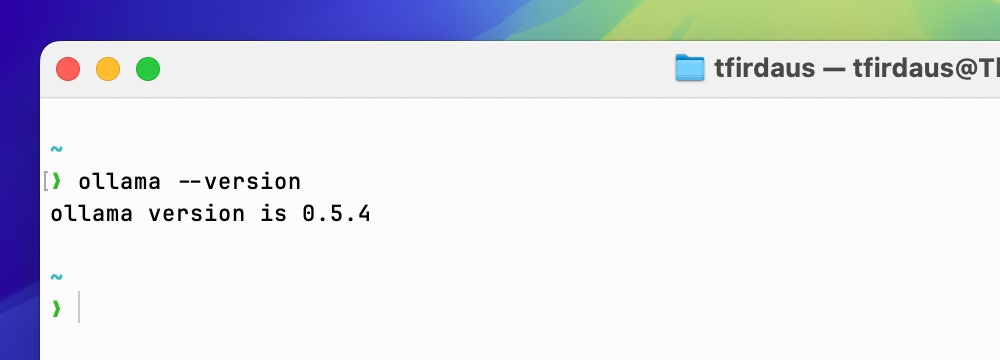
Sobald die Installation abgeschlossen ist, können Sie die Installation überprüfen, indem Sie ollama --version in Ihrem Terminal ausführen, um die aktuell installierte Version zu sehen.
Ollama ausführen
Nachdem wir Ollama installiert haben, können wir ein LLM damit ausführen. Wir können ein LLM aus ihrer Modellbibliothek auswählen.
In diesem Beispiel werden wir das llama3.2 Modell ausführen.
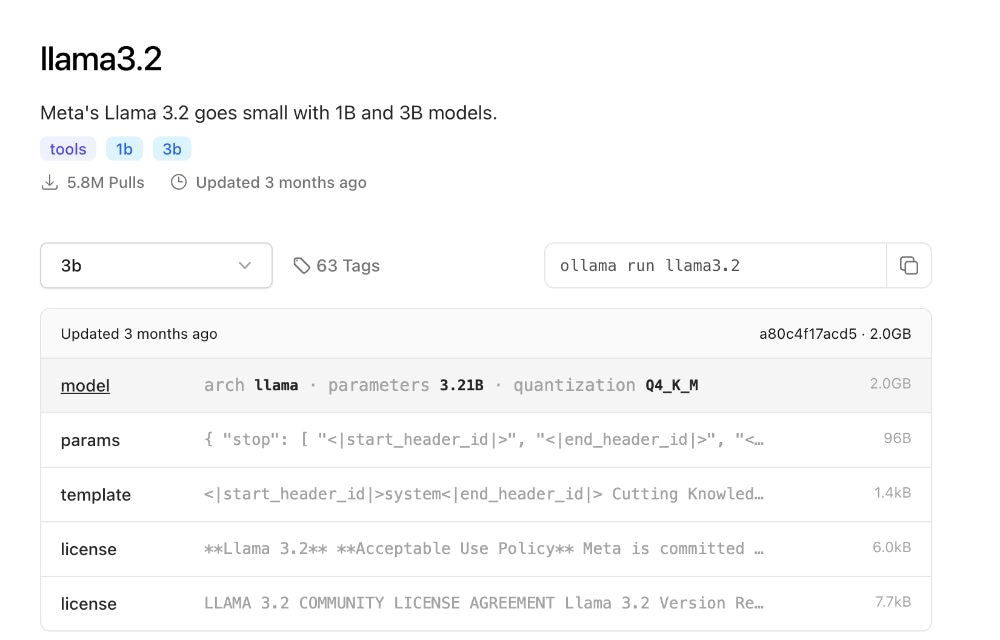
llama3.2 ist ein Modell von Meta, das für Aufgaben wie Inhaltserstellung, Zusammenfassungen und retrieval-augmented generation (RAG) entwickelt wurde. Es unterstützt mehrere Sprachen, darunter Englisch, Spanisch und Französisch, und ist kompakt, was es perfekt für leichte Anwendungen macht. Wenn Sie mehr Leistung benötigen, können Sie sich für ein größeres Modell wie llama3.3 mit 70 Milliarden Parametern entscheiden. Größere Modelle erfordern jedoch erheblich mehr Rechenressourcen, stellen Sie also sicher, dass Ihr System damit umgehen kann, bevor Sie den Wechsel vornehmen.
Um llama3.2 mit Ollama zu verwenden, geben wir ein:
ollama run llama3.2
Wenn dies das erste Mal ist, dass Sie dieses Modell ausführen, wird Ollama die Modell-Dateien herunterladen und auf Ihrem Computer zwischenspeichern. Dieser Prozess kann je nach Internetgeschwindigkeit einige Minuten dauern.
Nach dem Download können wir direkt im Terminal mit dem Modell interagieren. Es wird Ihnen eine Eingabeaufforderung anzeigen, bei der Sie Ihre Eingabe tätigen können, und das Modell wird eine Antwort basierend auf Ihrer Eingabe generieren.
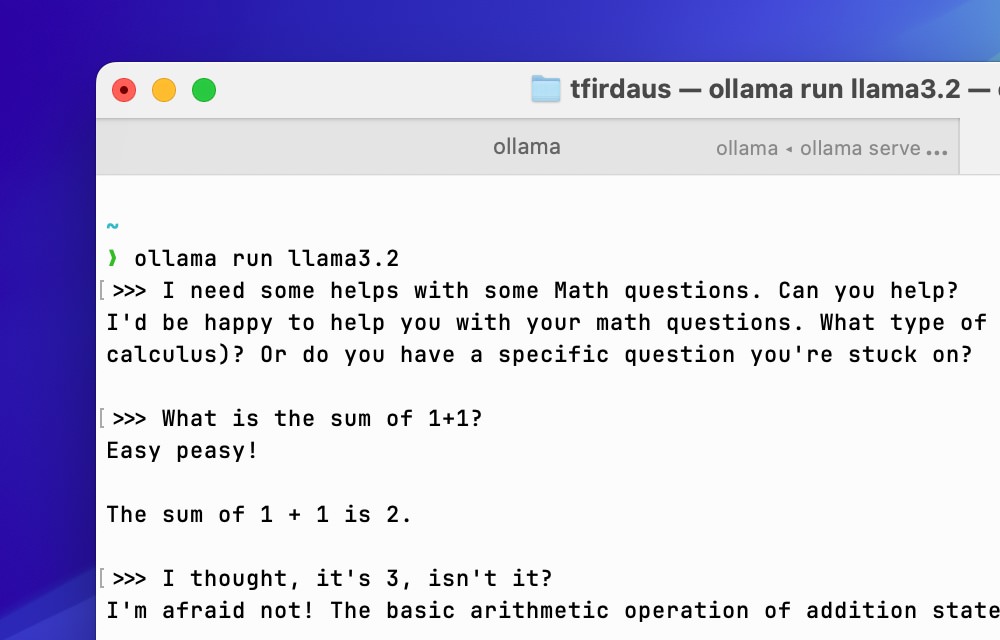
Um die Interaktion mit dem aktuellen Modell im Terminal zu beenden, können Sie /bye eingeben oder Ctrl/Cmd + D auf Ihrer Tastatur drücken.
Ollama API
Ollama stellt eine API zur Verfügung, mit der Sie programmgesteuert mit seinen Modellen interagieren können. Diese können Sie in Ihre Anwendungen, Websites oder andere Projekte integrieren.
Standardmäßig ist die API unter http://127.0.0.1:11434 zugänglich. Nachfolgend sind einige der wichtigsten Endpunkte aufgeführt, die Sie für diese Zwecke nutzen können:
| Endpunkt | Erklärung |
|---|---|
POST /api/generate |
Generieren Sie eine Antwort für eine gegebene Eingabe mit einem bereitgestellten Modell. |
POST /api/embed |
Generieren Sie ein Embedding für einen gegebenen Text mit einem bereitgestellten Modell. |
GET /api/tags |
Liste verfügbarer Modelle auf dem lokalen Gerät. |
GET /api/ps |
Liste der aktuell laufenden Modelle. |
Ollama stellt auch SDKs für Python und JavaScript zur Verfügung, um die Interaktion mit den APIs zu erleichtern.
OpenAI-Kompatibilität
Neben seiner eigenen API enthält Ollama eine Kompatibilitätsschicht für die OpenAI API. Dies ermöglicht es, den Code und die SDKs, die für die OpenAI API entwickelt wurden, mit Ollama wiederzuverwenden, was den Übergang zwischen beiden erleichtert.
Allerdings befindet sich die Kompatibilitätsschicht derzeit in der Beta-Phase, und einige Funktionen funktionieren möglicherweise noch nicht einwandfrei. Für die beste Erfahrung wird empfohlen, direkt die API von Ollama zu verwenden.
Fazit
Ollama ist ein leistungsstarkes und flexibles Tool, um KI lokal auszuführen. Es bietet Privatsphäre, Zuverlässigkeit und vollständige Kontrolle über die Modelle, die Sie verwenden.
Mit seiner API und den Werkzeugen eröffnet Ollama endlose Möglichkeiten, KI in Ihre Projekte zu integrieren. Von der Generierung schneller Antworten bis hin zur Lösung komplexer Probleme bietet es eine nahtlose und private Erfahrung.
Bleiben Sie dran für weitere Tutorials, in denen wir fortgeschrittene Funktionen und Anwendungsfälle erkunden!




{kind=link}